I thought I had seen it all, dear readers. But now our first and second authors, who are in a student:professor relationship, want to have a programming contest among the two, and the problem is how to simulate data from Haberman’s interaction model (Haberman (2007)). Now, as a third author I cannot allow such extravagant behavior, can I. On the other hand, the problem is so interesting, and the two algorithms so fascinating, that I feel everyone should see them. So I publish them as Algorithm A and Algorithm B, along with some comments.
The interaction model
While not even mentioned at the career award session dedicated to Shelby Haberman at NCME 2019, his interaction model (IM) must be one of the brightest, practically most salient ideas in psychometrics since 2000. It plays a strategic role in dexter, and we have posted several times about it and will continue to do so in the future. The IM can be represented in several ways, each of them highlighting different aspects of interest and applicability:
- as a generalization of the Rasch model that relaxes conditional independence while retaining sufficient statistics and the immediate connection to the observable
- as an exponential family model that reproduces all aspects of the data relevant to classical test theory: i.e., the score distribution, the item difficulties, and the item-total correlations
- as a Rasch model where item difficulty depends both on the item and on the total score.
In other posts, we have already commented on the usefulness of these properties in various practical situations. When devising a strategy to simulate from the model, the third aspect seems the most promising.
The interaction model can be expressed as a generalization of the Rasch model where item difficulty is a linear function of the test-score: \[\begin{align*} P(\mathbf{X}=\mathbf{x}|\theta) &\propto \exp(\theta r - \sum_i \delta_{ri} x_i) \end{align*}\]where \(\delta_{ri}=\delta_i-r\sigma_i\) for any possible sum score \(r\).
As an illustration, let us simulate data from an interaction model and use these to estimate a Rasch model separately for persons with the same test score (provided there are enough of them):
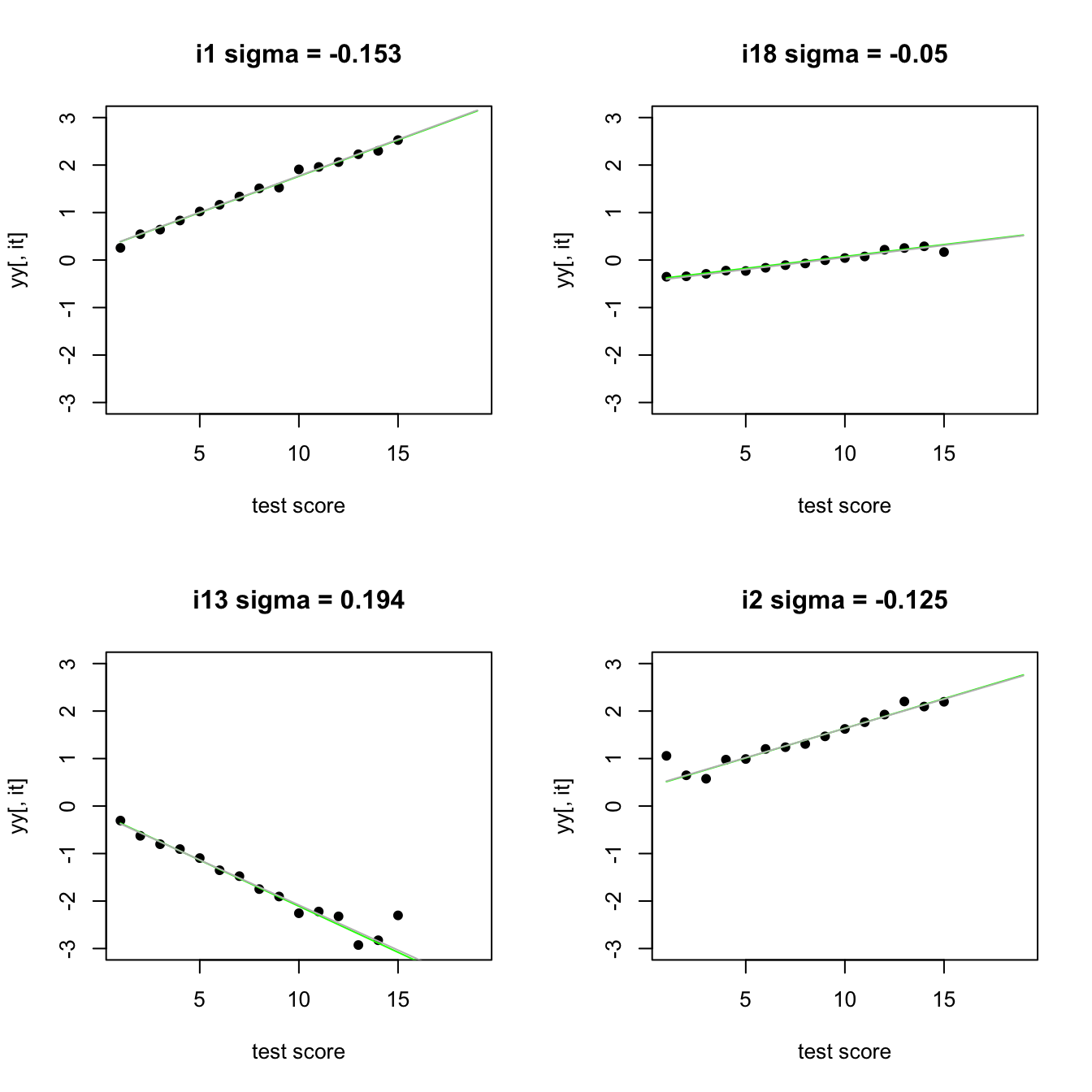
The dots are the estimated Rasch item parameters for each score-group, the green line represents the model from which we simulated, and the gray curve is obtained when we fit an interaction model to the simulated data. Two things are worth noting. First, we need very large samples to make such plots. Second, when we do have large samples, we often observe a linear relationship between item difficulty and test score. For some reason, the interaction model seems to describe educational data quite well.
Anyway. We have simulated data from the interaction model but the original question was how to do exactly that. Simulating from the Rasch model is fairly trivial. Given a vector of item difficulties, delta, and a sample from the ability distribution, theta, the R function is a one-liner:
simRasch<-function(theta, delta)
{
1*(rlogis(length(delta), 0, 1) <= (theta-delta))
}To simulate responses from the interaction model, we can apply this at each distinct test score \(r\) with score-specific item difficulties \(\delta_{ri}=\delta_i-r\sigma_i\) rather than simply \(\delta_i\). But this is not all, as the responses conditional on a given test-score are not independent. The two algorithms presented here differ in how they tackle this dependency: one samples item parameters directly while the other one relies on a simple rejection algorithm.
Algorithm A: rejection sampling
As mentioned above, the interaction model preserves the item difficulties, the item-total correlations, and the score distribution, so we enter the simulation with three inputs: delta, sigma, and scoretab. We sample from the discrete score distribution, scoretab, and, since the interaction model maps sum scores to ability estimates, we attach those from a look-up table easily produced with dexter. (For those who prefer to sample from the ability distribution, we will show in the Appendix how to derive the score distribution from that.)
We then go over all simulated ‘examinees’ and we simulate responses from the Rasch model, with theta and item difficulties both matching the person’s score, until the simulated sum score equals the true one. For zero and perfect scores, we simply take vectors of 0 or 1. In R:
sim_IM <-function(delta, sigma, scoretab)
{
nI = length(delta)
nP = sum(scoretab)
y = rep(0, nI)
x = matrix(0, nP, nI)
# nP samples from the score distribution:
s = sample(0:nI, nP, replace=TRUE, prob=scoretab)
# attach the MLE estimates of theta:
ab = makeMLE(delta,sigma)
for (p in 1:nP)
{
if ((s[p]>0)&(s[p]<nI))
{
# compute item difficulties at score s[p]:
delta_s = delta - s[p]*sigma
repeat{
y = simRasch(theta=ab[s[p]+1], delta=delta_s)
if (sum(y)==s[p]) break
}
x[p,] = y
}
if (s[p]==0) x[p,] = rep(0,nI)
if (s[p]==nI) x[p,] = rep(1,nI)
}
return(x)
}The ability that matches a person’s score is the maximum likelihood estimate (MLE); i.e., the ability for which the expected score is equal to the observed one. In fact, any theta would do, eventually, but then we would have to wait much longer until the sum of the simulated response pattern matches the target sum score. For the aficionados, our makeMLE function is provided in the Appendix.
Algorithm B: sampling without replacement
The dependence between responses conditional on the sum score can be approached by simulating them sequentially and adjusting the probability after each draw, much as we would take samples from an urn without replacement. An algorithm can be constructed based on the observation that at any sum score \(r\), the probability that item \(i\) is answered correctly can be computed as \[P(X_i=1|r) = \frac{b_{ri}\gamma_{r-1}(\mathbf{b}_{r}[-i])}{\gamma_{r}(\mathbf{b}_{r})}\] where \(b_{ri} = \exp(-\delta_{ri}) = \exp[-(\delta_i-\sigma_ir )]\), \(\mathbf{b}_{r}[-i]\) is the vector of item parameters without the \(i\)th entry, and \(\gamma_{s}(\mathbf{b})\) the elementary symmetric function of \(\mathbf{b}\) of order \(s\). Note the use of an R-like notation to express dropping the \(i\)-th element.
This may be a bit subtle, so we illustrate what happens with a small example. Suppose that we have a test of three items. If the test score is 0 or 3, there is nothing to do because there is only one possible response pattern in each case. Suppose \(x_+=2\), and let us start by simulating the response to the third item. This is a Bernoulli experiment with the probability of success given by \[ P(X_3=1|X_+ = 2, \boldsymbol{\delta}_2) = \frac{b_{23}(b_{21}+b_{22})}{b_{21}b_{22}+b_{21}b_{23}+b_{22}b_{23}} \] with the ESF written out. If the experiment fails, then we are done because, with \(x_+=2\), the responses to the first two items must be correct. If it succeeds, we are left with a test of two items and a sum score of 1. To simulate the response to item 2, we perform another Bernoulli experiment with a probability of success \[ P(X_2=1|X_+ = 1, \boldsymbol{\delta}_2) = \frac{b_{22}b_{21}}{b_{21}+b_{22}}. \] Regardless of the outcome, the answer to the first item is now also determined because the sum score must be 2. The case of \(x_+=1\) is handled in a similar fashion, and don’t forget to replace \(\boldsymbol{\delta}_2\) with \(\boldsymbol{\delta}_1\) because we are simulating from the interaction model, remember?
The computational burden with Algorithm B is in the calculation of the elementary symmetric functions. What is minimally required is a \(n+1\) by \(n\) matrix \(\mathbf{G}_{x_+}\) whose columns contain the elementary functions for \(\mathbf{b}_{x_+}[1], \mathbf{b}_{x_+}[1:2], \dots, \mathbf{b}_{x_+}[1:n]\). Since we need \(\mathbf{G}_{x_+}\) for all possible test-scores \(x_+\), we make a three way array \(\mathbf{G}\): test-scores by number of test-scores by number of items. The entries of \(\mathbf{G}\) are: \[ g_{rsi} = \left\{ \begin{array}{cl} \gamma_{s}(\mathbf{b}_{r}[1:i]) & \text{if $s\leq i$}\\ 0 & \text{if $s>i$} \end{array} \right. \]
where the first two indices \(r\) and \(s\) run from zero to \(n\), and the third index \(i\) runs from \(1\) to \(n\). The elementary symmetric functions are calculated using the sum-algorithm. Here is the necessary code in R:
elsymRM <-function(b)
{
n=length(b)
g=matrix(0,n+1)
g[1]=1; g[2]=b[1]
if (n>1)
{
for (j in 2:n)
{
for (s in (j+1):2) g[s]=g[s]+g[s-1]*b[j]
}
}
return(g)
}
makeG <-function(b_s)
{
nI=ncol(b_s)
G = array(0,c(nI+1,nI+1,nI))
for (s in 0:nI)
{
for (i in nI:1)
{
G[s+1,1:(i+1),i] = elsymRM(b_s[s+1,1:i])
}
}
return(G)
}It is now straightforward to implement the simulation algorithm itself:
sim_IMB <-function(delta, sigma, scoretab)
{
nI = length(delta)
nP = sum(scoretab)
x = matrix(0, nP, nI)
r = sample(0:nI, nP, replace=TRUE, prob=scoretab)
b_r = matrix(0, nI+1, nI)
for (s in 0:nI) b_r[s+1,] = exp(-(delta - s*sigma))
# so far, as in Algorith A, but now compute the
# matrix of elementary symmetric functions rather
# than the MLE of ability at each sum score
G = makeG(b_r)
for (p in 1:nP)
{
s = r[p]
for (i in nI:1)
{
if (s == 0) break
if (s == i)
{
x[p, 1:i] = 1
break
}
pi_s = (b_r[r[p]+1, i] * G[r[p]+1, s, i-1])/G[r[p]+1, s+1, i]
if (runif(1) <= pi_s)
{
x[p, i] = 1
s = s - 1
}
}
}
return(x)
}Note that both \(\mathbf{b}\) and \(\mathbf{G}\) are pre-calculated outside of the loop over persons. Note further that we break as soon as we know all remaining responses.
Comparing the two algorithms
Speed
Both algorithms are fast enough for practical purposes even though they are in plain R, not your fastest language. Additional speed can be gained by rewriting the critical parts in FORTRAN or C. Algorithm A turns out to be faster, which is worth mentioning because the idea of rejection sampling is inherently associated with some waste.
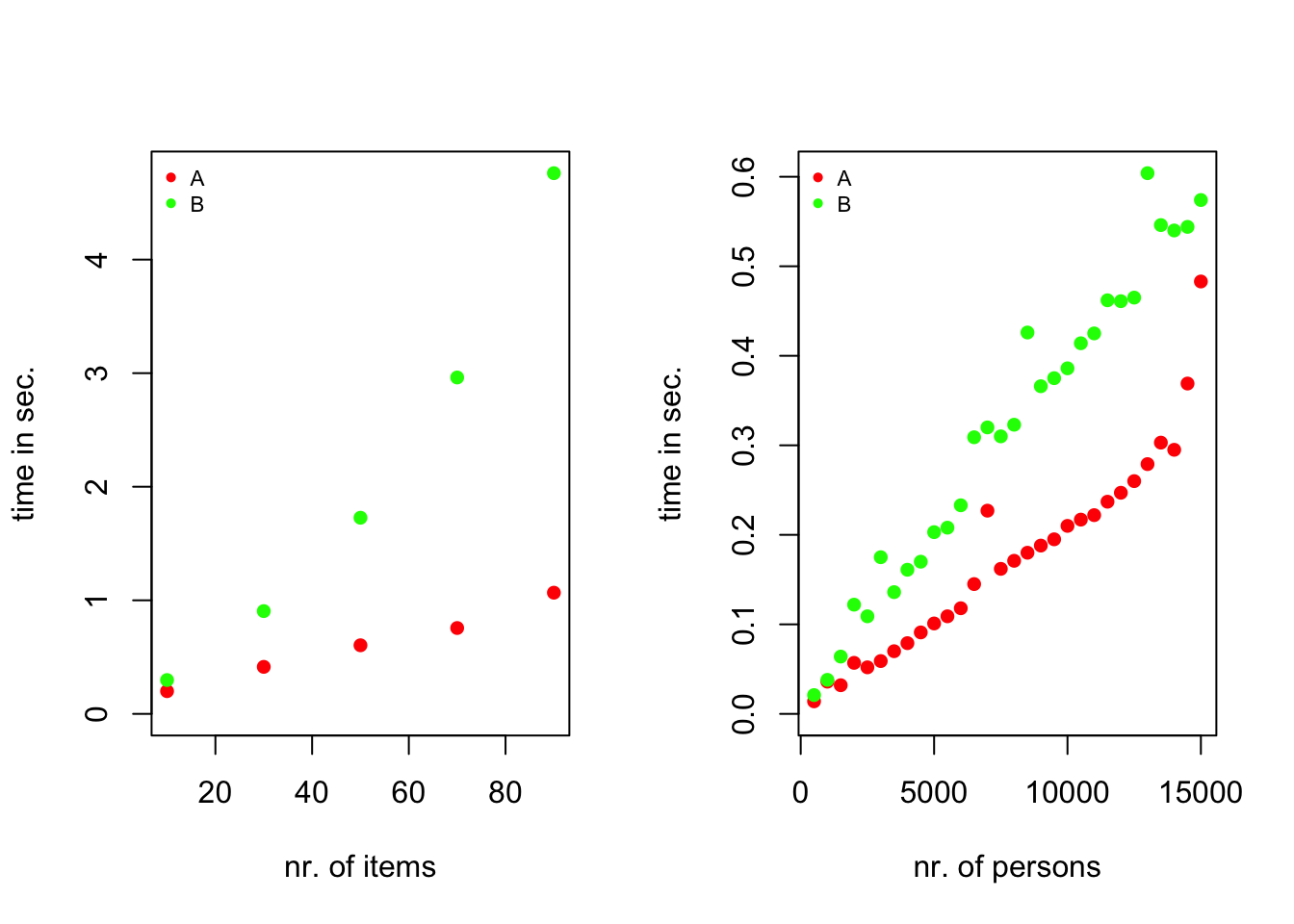
Stability
Note that the plots do not show times for more than a hundred items. Algorithm B depends on computing the elementary symmetric functions, the gentlest monster you have ever encountered, but still a monster in your backyard. We have used the sum-algorithm, which is perfectly reliable for tests of reasonable length, say up to 100 items. In the interaction model the item difficulties can become large quite rapidly such that, for longer tests, it may be compromised by numeric overflow. For example, with \(150\) items and \(x_+\) equal to \(145\):
delta = runif(150,-0.5,1.5)
sigma = runif(150,-0.5,0.5)
s = 145
b_r = exp(-(delta-s*sigma))
esf = elsymRM(b_r)
max(esf)## [1] InfThe ESF are indispensable when dealing with test data and psychometric models, they are ubiquitous in dexter, but programming them for production purposes requires extra care. Our second author has developed a special FORTRAN library for dealing with very large numbers, somewhat similar to R package Brobdingnag (Hankin (2007)) but better and, as it happens much too often with this author, unpublished. We will revisit the problem in the future.
Appendix
Simulate score distribution from a continuous distribution of ability
In both algorithms, we sampled “persons” from a discrete distribution of sum scores. This may seem unusual and, more importantly: where do we get that? Readers may be more accustomed to sampling ability values from a continuous distribution, with the normal distribution as a particularly popular choice. Although there is no compelling reason to believe that abilities must be normally distributed, it is not implausible, and everyone knows the rnorm function in R (R Development Core Team (2005)).
To get samples from a discrete distribution of sum scores starting with samples from a continuous distribution and a set of item parameters, we may consider that, since \[ P(x_+) = \int P(x_+|\theta) f(\theta) d\theta \] we can sample \(\theta\) from \(f(\theta)\) and subsequently sample \(x_+\) from \(P(x_+|\theta)\).
What is \(P(x_+|\theta)\)? We find it if we write \[ P(\mathbf{x}|\theta) = \frac{e^{x_+\theta}\prod_i b^{x_i}_{x_+i}}{\sum_s e^{s\theta} \gamma_s(\mathbf{b}_s)} =\frac{\prod_i b^{x_i}_{x_+i}}{\gamma_{x_+}(\mathbf{b}_{x_+})} \frac{e^{x_+\theta}\gamma_{x_+}(\mathbf{b}_{x_+})}{\sum_s e^{s\theta} \gamma_s(\mathbf{b}_s)} = P(\mathbf{x}|x_+)P(x_+|\theta) \] Thus, \[ P(x_+|\theta) \propto e^{x_+\theta}\gamma_{x_+}(\mathbf{b}_{x_+}) \] Conveniently, we have already computed the elementary symmetric functions and saved them in the matrix, \(\mathbf{G}\), so:
sample_scores <-function(theta, G)
{
nI = dim(G)[3]
nP = length(theta)
scores = rep(0, nP)
for (p in 1:nP)
{
prop = rep(0, nI+1)
for (s in 0:nI)
{
prop[s+1] = exp(theta[p]*s) * G[s+1, s+1, nI]
}
scores[p] = sample(0:nI, 1, prob=prop)
}
return(scores)
}MakeMLE
makeMLE<-function(delta, sigma)
{
nI = length(delta)
first = seq(1,2*nI,2)
last = first+1
a = rep(c(0,1), nI)
b = rep(1,2*nI)
ab = rep(0,nI-2)
for (s in 1:(nI-1))
{
eta = delta - s*sigma
b[last] = exp(-eta)
ab[s] = dexter:::theta_MLE(b,a,first,last)$theta[s+1]
}
ab = c(-Inf,ab,Inf)
return(ab)
}References
Haberman, Shelby J. 2007. “The Interaction Model.” In Multivariate and Mixture Distribution Rasch Models: Extensions and Applications, edited by M. von Davier and C.H. Carstensen, 201–16. New York: Springer.
Hankin, RKS. 2007. “Very Large Numbers in R: Introducing Package Brobdingnag.” R News 7 (3): 15—16.
R Development Core Team. 2005. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org.